ALFIE:一种基于DRL的新型短视频自适应预取算法
ALFIE: NEURAL-REINFORCED ADAPTIVE PREFETCHING FOR SHORT VIDEOS
ICME:CCF B会议
关键词:短视频自适应预取
背景
为了提供流畅的播放并避免重新缓冲延迟,通常使用预取即将播放的视频。而当前的预取设计在处理带宽开销方面存在不足,用户可能退出而不是继续观看已预取下载的块,由此导致带宽浪费。
目前的简单策略是,预取固定数量的视频以及每个视频的前几个块。
目前预取策略
通常遵循简单的静态策略:始终从推荐队列的顶部下载前 i 个视频,并且对于每个视频始终下载前 j 个块。预取是按顺序执行的。当前视频的下载优先级由播放器控制,与预取无关。
问题分析
我们将这一系列政策表示为 S-i-j。考虑此静态策略的两个实例:S-3-3 和 S-5-6。
作者使用模拟器重播静态预取策略,获得带宽开销(即总带宽消耗减去消耗的视频块的总大小)和退出开销(即由于退出而预取但未被观看的所有数据)。作者发现:
1、静态预取会导致大量带宽开销,包括退出开销。
2、大多数的会话消耗的视频不超过 60 个。近 52% 的会话观看的短视频不超过 6 个,意味着大量用户在观看几个视频后就离开了。在极端情况下,即 29% 的会话仅消耗一个视频,任何预取的数据都会被放弃。这种用户行为是退出开销的主要原因。
3、静态策略在不同环境中效果不佳。
4、当网络带宽较低和/或用户倾向于快速滑动时,S-5-6 更好,因为它一次预取更多的块,重新缓冲时间和启动延迟相应变少。在其他场景中,S-3-3更好,因为它产生的带宽开销更少,但 QoE 非常相似。
工作
1、作者构建了 Alfie,一种基于DRL 的新型短视频自适应预取算法,来解决这一问题。Alfie根据网络条件和用户观看模式来调整预取,同时考虑减少带宽开销和退出开销。
参考用户观看模式,随着用户观看更多视频,用户离开的可能性也不断增加,预取应该更加保守。如果用户的观看行为是基于历史数据的典型行为(通常只在离开之前观看几个视频),预取应该更加保守。如果用户行为是长尾状态,则可以更加积极地进行预取。
参考网络因素,如果网络条件可能恶化,可以选择更多地预取以应对带宽短缺。
2、作者采用深度强化学习(DRL)进行预测。该DRL 模型利用一组有关用户行为(例如历史会话持续时间、过去视频的观看时间)、网络状况(例如最近的网络带宽)和即将播放的视频的特征作为环境状态,并学习优化策略QoE 增益和带宽开销的长期利益。
3、开发了一个短视频流模拟器来训练 Alfie。
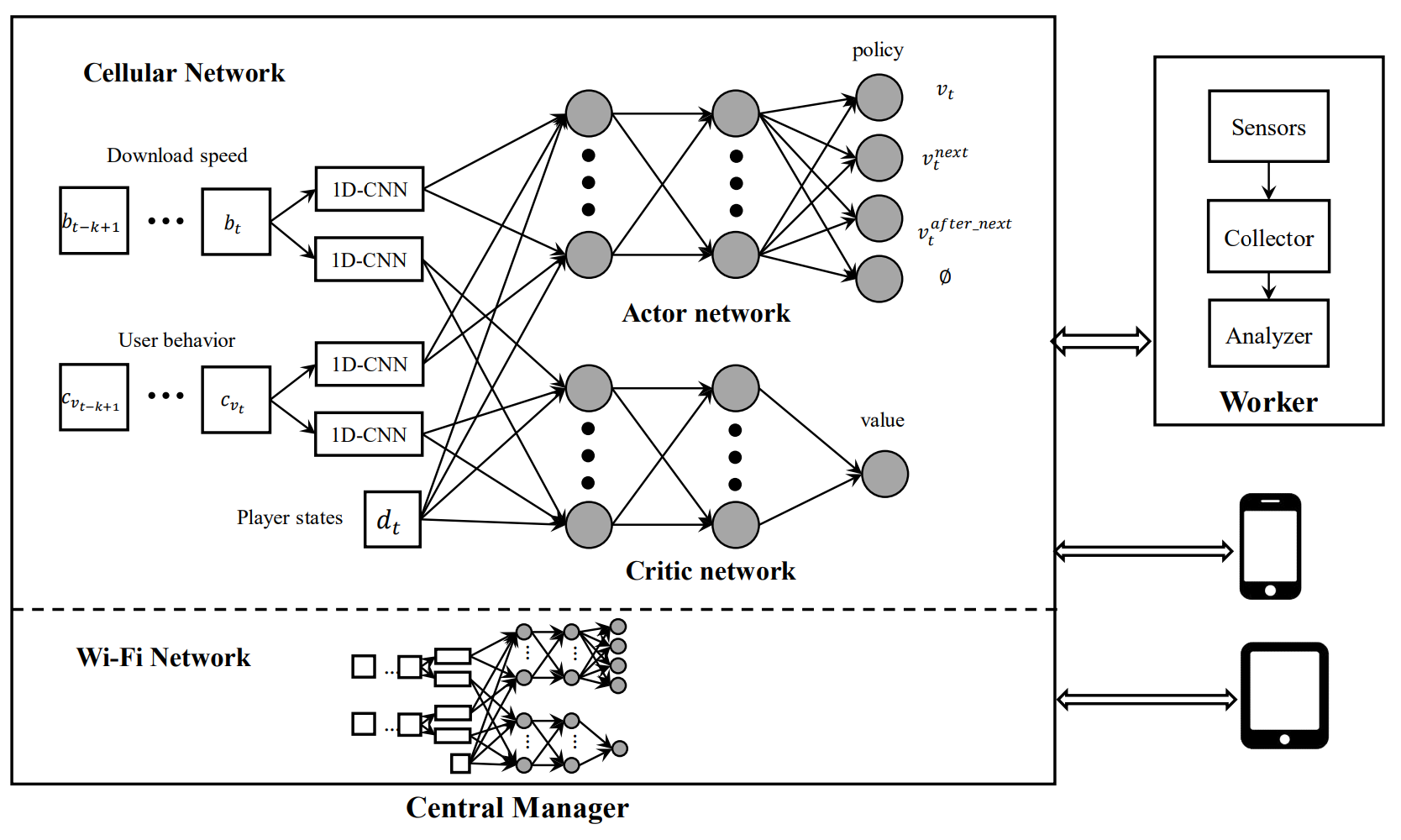
Alfie 的详细设计
它由 RL 模块、慢启动机制、短视频流模拟器组成
基于DRL 模拟预取
状态空间
在 Alfie 中,在给定步骤 i 处,状态空间 Si = [Ui, Wi, Pi, Vi] 包含以下内容:
- 用户行为特征Ui = [Fi, Ei],Fi 表示过去 M 个视频中每个视频的观看时间,即 Fi = [f0, f1,… , fM ] 其中 f0 是用户在当前视频上花费的总时间。用户的退出行为Ei= [e0, e−1, …, e−K] 描述了最近 K 个会话中(从用户进入到离开应用程序为一个会话)观看的视频数量,其中 e0 是当前会话中观看的视频数量。
- 网络吞吐量Wi = [n0, . 。 。 ,n1−L],表示最近完成下载的L个块的平均下载吞吐量。
- 播放信息Pi = [Bi,gi]。Bi = [b0,… 。 。 , bN ],表示当前视频+推荐队列 中所有 N 个即将发布的视频的下载数据大小,其中b0是当前视频的下载大小,b1是队列顶部第一个视频的预取数据大小。gi 表示当前视频的播放进度。
- 块信息Vi = [v0,… 。 。 , vN−1],表示所有 N 个即将发布的视频的候选块的大小,
行为空间
由标量 Ai 表示,它取 0 到 N 之间的整数值。当 Ai = 0 时,意味着 Alfie 选择不预取任何内容。当Ai = x 时,Alfie 从推荐队列中预取第 x 个视频不在缓冲区中的下一个块。
每当 Alfie 发现第一个即将播放的视频根本没有被预取时,它总是选择在这一步中预取它,即 Ai = 1。
奖励函数
奖励函数 R(Si, Ai, Si+1) 由两个方面组成,Ridle代表没有任何动作时的奖励,Rprefetch是发生预取的奖励。如下所示:
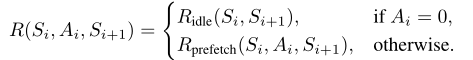
当RL代理选择Ridle:
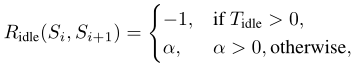
Tidle 表示在从 Si 到 Si+1 的空闲期间当前视频的重新缓冲时间(当下一个要播放的块在播放时间之前没有下载时,就会发生重新缓冲,每次发生重新缓冲时,我们都会记录其持续时间)。
这里 α > 0 是一个正的奖励系数,控制了QoE和带宽开销之间的权衡。如果α很大,代理倾向于更频繁地不做预取,因为即使经常发生重新缓冲事件,它仍然可以获得奖励;如果α接近0,则代理会更积极地进行预取。
当RL代理选择R prefetch ( S i , A i , S i +1 ):
输入:Ai:选择预取的视频; j:Ai中要预取的chunk的位置; T (Si, Ai, Si+1):下载块 j 期间的重新缓冲时间
1、获取当前会话中剩余要播放的视频数量h。
2、如果T (Si, Ai, Si+1) > 0,Rprefetch=-1,表示惩罚;如果Ai > h,Rprefetch=-1,由于用户退出而不会观看视频,则对下载该视频进行惩罚。否则,根据历史记录获取用户花在视频Ai上的时间s。
3、如果j > s,Rprefetch=-1,块 j 的时间戳超出用户停留时间,则惩罚滑动开销。否则,Rprefetch = β ∗ (s − j)/s
输出:Rprefetch
慢启动
最初在观看会话开始时,窗口大小仅为一,这意味着 Alfie 仅预取一个视频。随着观看的视频数量增加 1 个,它会增加 1,直到达到 N(推荐队列大小)。
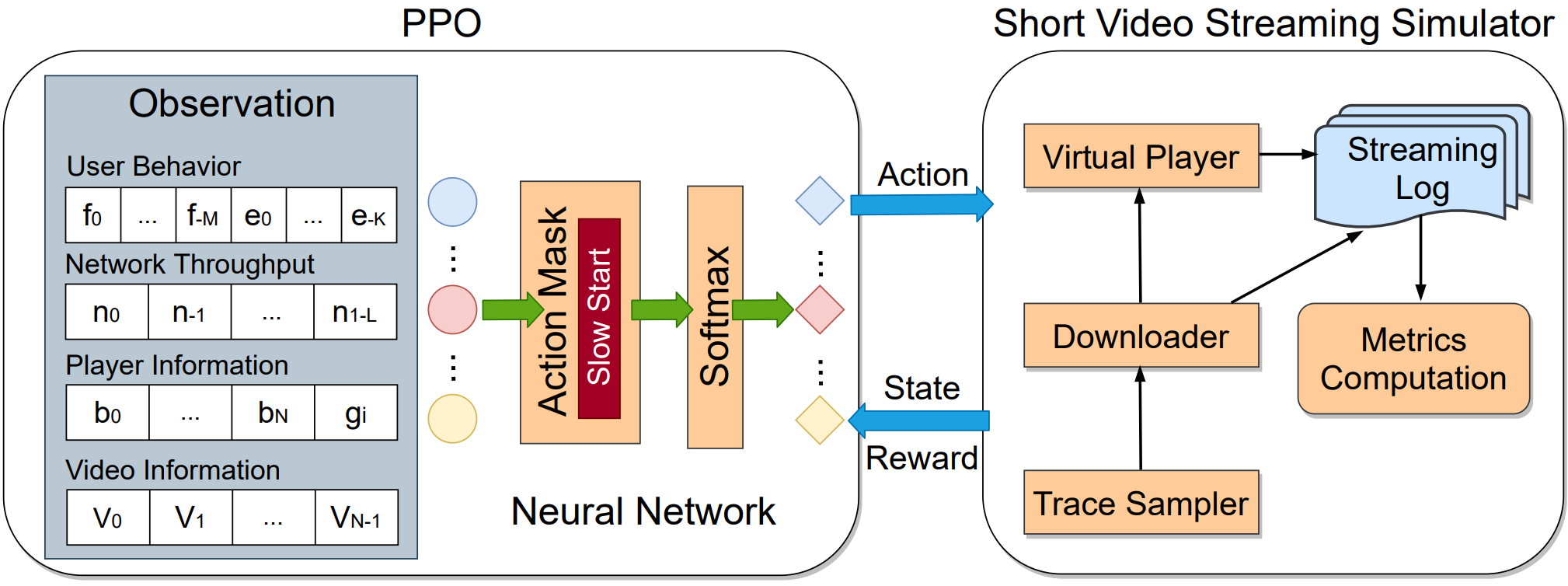
模拟器
Alfie的模拟器工作如下:数据采样器加载会话数据和网络数据,并将所有用户滑动和退出事件注入事件队列。在流媒体传输期间,下载器使用来自采样器和RL模型的动作执行下载事件,包括当前视频的下载和预取即将到来的视频。虚拟播放器控制播放并记录重新缓冲和滑动事件。将性能指标(例如重新缓冲时间和开销)记录在日志中。
模拟器可以在仅8分钟内模拟244小时的短视频流媒体。
性能指标
使用四个性能指标:两个用于QoE(用户体验质量)和两个用于带宽开销。(i)重新缓冲时间T,(ii) 启动延迟D:用户滑动事件和播放开始时间之间的延迟;(iii)滑动开销Ws(iv)退出开销We。
对于短视频的QoE并不需要考虑视频比特率,因为它们的比特率是在生成推荐队列时确定的。数据库中的所有短视频均采用可变比特率的 VBR 编码。
作者通过结合上述所有四个指标来考虑以下负效用,U 越小越好(毫秒为单位),因为指标都反映了负面影响:
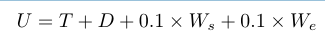
实验设计
将 Alfie 与最先进的预取方法进行比较:
1、Oracle:在已知用户未来信息(即用户滑动和退出时间)的理想情况下,按顺序下载块(baseline);
2、Next-One(抖音采用):它总是完整下载当前视频,然后开始完整下载下一个视频。然后它保持空闲状态(不再预取),直到发生滑动事件。
3、Static:简单的静态策略:始终从推荐队列的顶部下载前 i 个视频,并且对于每个视频始终下载前 j 个块。预取是按顺序执行的。当前视频的下载优先级由播放器控制,与预取无关。作者考虑了S-3-3 、 S-5-6 、S-5-12。
4、LiveClip:一种基于学习的短视频流预取算法。它从当前视频和接下来的两个即将播放的视频中选择块进行下载。
作者在低(平均 1.48Mbps)和高(平均 Mbps)带宽场景下进行了实验。实验结果表明:
Alfie 提供了带宽高效的预取策略,有效降低了带宽开销尤其是出口开销。
Alfie 可以将吞吐量历史信息合并到其状态空间中,以针对近期网络特性进行优化。
作者在用户短(平均 4.9 秒)和长(平均 45 秒)滑动间隔的场景下进行实验,并为这两种场景使用相同的网络轨迹,结果表明:
1、当用户执行快速滑动时,与最佳静态策略S-5-12相比,Alfie在重新缓冲时间上实现了13.3%的改进;
2、当用户执行快速滑动时,Next-One、S-3-3 和 LiveClip 在 QoE 指标中表现不佳,因为它们都在固定的短范围内预取,无法很好地处理快速滑动事件。 LiveClip 性能不佳的另一个原因是它采用恒定比特率 (CBR) 编码,这使得它无法适应不同的块大小。
3、当滑动间隔较长时, Alfie 在重新缓冲时间方面比 Next-One 稍差,因为 Next-One 会以牺牲带宽为代价进行积极预取。
Alfie 学到的规则
Alfie 倾向于在较低带宽网络中更积极地预取以避免重新缓冲,并在带宽较高时保守地预取。
在用户快速滑动场景中,Alfie 优先选择每个视频的第一个块,然后再显示后续内容。
会议即将结束时趋于保守。
 wechat
wechat